

Build a Machine Learning Web App with Streamlit and Python.
Build your first machine learning web app with the Streamlit library in
Python. By the end of this project, you are going to get comfortable with using
Python and Streamlit to build beautiful and interactive web apps with zero web
development experience!
Prior experience with writing simple Python scripts and using pandas for
data manipulation is recommended. It is required that you have an understanding
of Logistic Regression, Support Vector Machines, and Random Forest Classifiers
and how to use them in scikit-learn.
Support Vector Machine (SVM): A Support Vector Machine (SVM) is a discriminative classifier formally defined by a separating hyperplane. In other words, given labeled training data (supervised learning), the algorithm outputs an optimal hyperplane which categorizes new examples. In two dimentional space this hyperplane is a line dividing a plane in two parts where in each class lay in either side.
Logistic Regression: is a Machine Learning classification algorithm that is used to predict the probability of a categorical dependent variable. In logistic regression, the dependent variable is a binary variable that contains data coded as 1 (yes, success, etc.) or 0 (no, failure, etc.). In other words, the logistic regression model predicts P(Y=1) as a function of X.
Random Forest: Random forest classifier creates a set of decision trees from randomly selected subset of training set. It then aggregates the votes from different decision trees to decide the final class of the test object.
The objectives of our project:
1. Build interactive web applications with Streamlit and
Python.
2. Train Logistic Regression, Random Forest, and Support Vector Classifiers
using scikit-learn.
3. Plot evaluation metrics for binary classification algorithms.
The hands on project on Build a Machine Learning Web App with
Streamlit and Python is divided into following tasks:
Task 1: Project
Overview and Demo
This application shows the performance of the mentioned ML algorithms to predict the binary classification (edible or poisonous) of Mashrooms using the mushrooms dataset collected from UCI. The performance is shown here in terms of accuracy, precision, recall, confusion matrix, ROC curve, and precision-recall curve. The demo of our project is shown below:
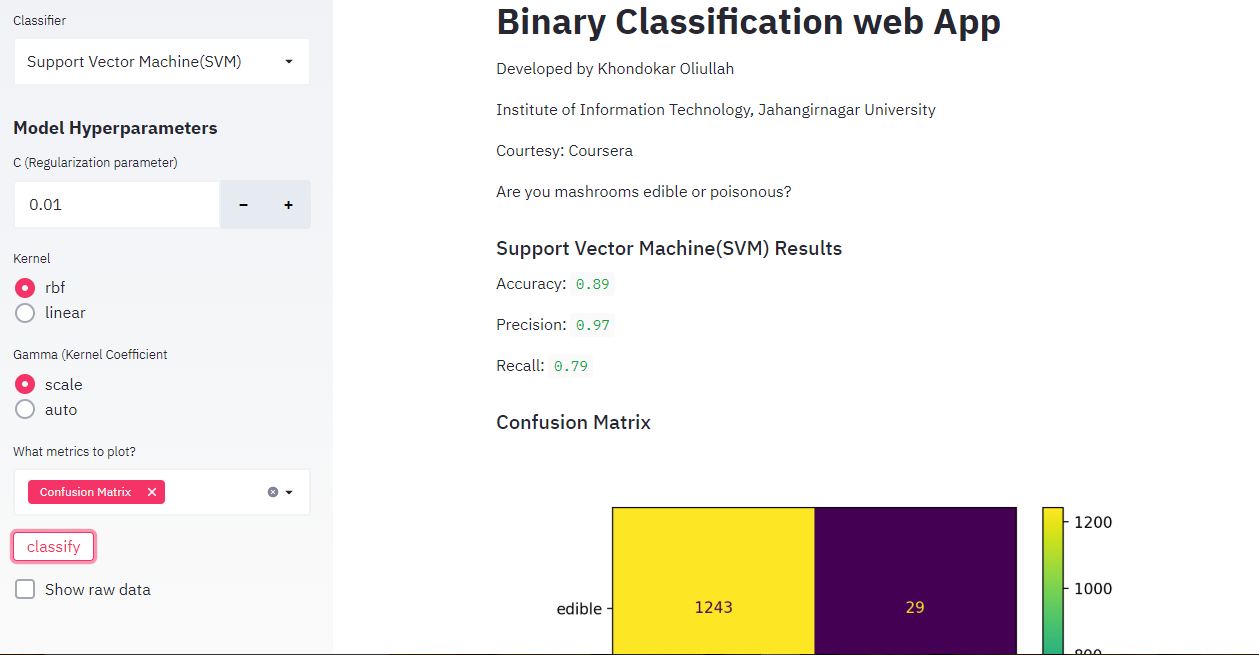
Fig: Screenshot of web app
Task 2: Turn Simple
Python Scripts into Web Apps
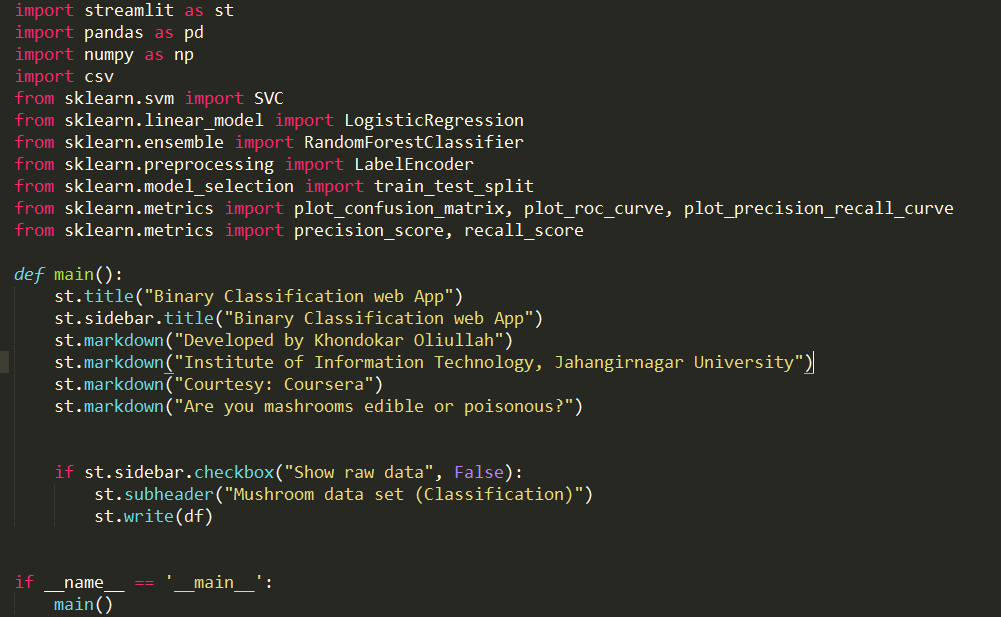
Task 3: Load the
Mushrooms Data Set

Task 4: Creating
Training and Test Sets

Task 5: Plot
Evaluation Metrics
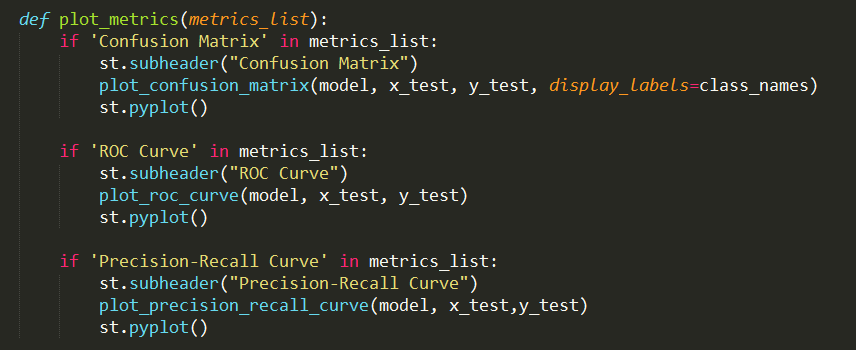
Task 6: Call Load Data and Split function to divide the data into a training set and Test set
Task 7: Training a Support Vector Classifier

Task 8: Train a
Logistic Regression Classifier

Task 9: Training a
Random Forest Classifier

Now, open the terminal using anaconda navigator.

Outcome: Some screenshots of the web app in the following.



N.B: You have to install Anaconda Navigator and Streamlit before starting the development.
Courtesy: Coursera and UCI




No comments